 Data is held in many forms, e.g. spreadsheets, presentation slides and documents. These are stored with meaningful names and attributes that enable information to be found.
Data is held in many forms, e.g. spreadsheets, presentation slides and documents. These are stored with meaningful names and attributes that enable information to be found.
However, information in such documents is not easy to combine or consolidate. Hence, systems provide forms into which data is input and then stored in databases using specified attributes.
Business intelligence tools are used incorporate this data into documents for presentation.
Some sources are known as the ‘master source’ of the data, for example, a finance system for costs, an HR system for skills and a corporate risk register for organisational level risks. Some contain master code schemes used in categorising data. Example common reference data includes payroll numbers, contract codes and departmental cost accounts.
The proposition underpinning the BIG Model is that all this data is collated into a data warehouse from the master sources before it is extracted with business intelligence tools to create reports.
The combination of information from multiple sources requires common references for the source data. These common references must be used by all component systems. An implementation of the BIG approach starts with a strategy for common data structures.
Without a strategy, parochial solutions may emerge that cause integration problems. The strategy should include the design of a data warehouse, including the preferred methods of data assembly, systems integration and possible use of AI to fill the gaps and integrate.
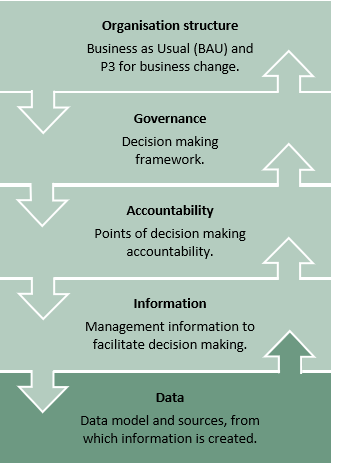
Once in place, BIG enables the organisation to run its governance from the Core P3M dataset, safe in the knowledge it can extend its data sources, serve its regular and ad hoc MI needs and most importantly - enable more informed decision making throughout.
The MI for each Governance Node has a requirements-driven, outcome-focused basis. Governance Nodes describe what information is needed, at what frequency and in what form to enable the key stakeholders to collaborate. A common data language means that the sources for all this information can be managed more effectively with data sharing becoming more effective and efficient than point to point information transmission.
Local areas can use suitable tools and methods for their local needs yet still be compliant with the overall organisation wide governance needs.
Development and evolution of a data model
It is unlikely that any organisation will be able to specify all its MI needs for all of its governance nodes up front. Requirements will develop and extend with time. Some areas may develop faster than others.
A standard data model of preferences for table and field definitions is just a starting point. New requirements will follow and if the initial design is rich and flexible, there will be fewer data customisations needed as time progresses.
The data design also enables an organisation to separate its core data (e.g. Task ID) and metadata likely to be organisation specific (e.g. Location).
This means that as organisations develop and evolve Core MI needs for each Governance Node (see the Accountability section), it is possible to extend and localise the data model without compromising its integrity.
Technology Considerations
The BIG approach is not prescriptive about technology and recognises that many suitable solutions may be in use. The sample data model could theoretically be provided by one business wide solution but his would mean the data formats and reporting could be controlled from one place.
However, one size rarely fits all and organisations find that people keep data in their own ways or in local systems that support specific needs. For example, organisations may use similar but different applications in different circumstances, such Primavera for large programmes, Microsoft Project for projects and Jira for agile delivery.
On top of this, Main Board data may be stored in a board portal solution and finance data in an Oracle or SAP Finance system. The challenge is to configure and operate them with the same code schemes so that data can be classified consistently across solutions.
Assuming the answer is to integrate data, there are options for how this may be approached. Does one solution become the master into which the others input data? Does each solution have integrations with the others it needs to share data with? Is data collected and integrated into a central data warehouse?
It is likely that an organisation has a finance system that contains the common (enterprise) reference data for cost tracking and revenue collection. It is common that the finance system is the backbone for the data needed in the BIG model.
Whatever the mix of tools and data sources, it is sensible to orchestrate data feeds using a common business cadence to gather and join the information from various sources.
Different users will work towards different events. For example, the end of a month when a finance process collects invoices and timesheets to calculate the actual cost position.
To enable this, an organisation may have a technology solution for master data management and an integration solution to pull together and connect related data.
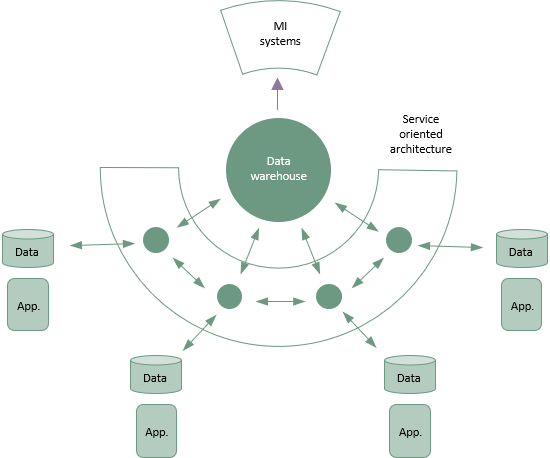
There may be a preference for a Data Platform (e.g. Amazon, Azure, Oracle, etc.) or a preference for technology to support Business Intelligence dashboards and reports (e.g. Power BI, Tableau, etc.). These need to be coordinated for effective delivery of information and knowledge to support the governance operation. Otherwise there could be a significant overhead in manually contriving a complete data picture (if even attempted). Everyone owning a component needs to understand the constraints they can work within.
Thank you to the Core P3M Data Club for providing this page.



